There is a serious limitation present in the RTM version of WCF 3.0/3.5 regarding control of WS-RM retry messages during a reliable session saga.
Let me try to explain the concept.
We have a sender (communication initiator) and a receiver (service). When a reliable session is constructed between the two, every message needs to come to the other side. In a request-reply world, the sender would be a client during the request phase. Then roles would switch during the response phase.
The problem arises when one of the sides does not get the message acknowledgement in time. WCF reliable messaging implementation retries the sending process and hopes for the acknowledgement. All is well.
The problem is that there is no way for the sending application to specify how long the retry timeout should be. There is a way to specify channel opening and closing timeouts, acknowledgement interval and more, but nothing will define how long should the initiator wait for message acks.
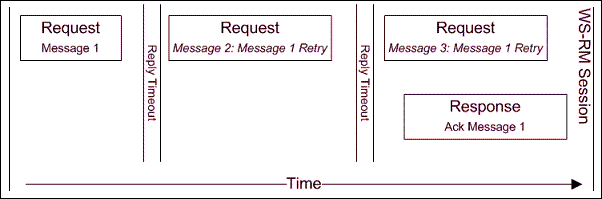
Let's talk about how WCF acknowledges messages.
During a request-reply exchange every request message is acknowledged in a response message. WS-RM SOAP headers regarding sequence definition (request) and acknowledgements (response) look like this:
a1 <r:Sequence s:mustUnderstand="1" u:Id="_2">
a2 <r:Identifier>urn:uuid:6c9d...ca90</r:Identifier>
a3 <r:MessageNumber>1</r:MessageNumber>
a4 </r:Sequence>
b1 <r:SequenceAcknowledgement u:Id="_3">
b2 <r:Identifier>urn:uuid:6c99...ca290</r:Identifier>
b3 <r:AcknowledgementRange Lower="1" Upper="1"/>
b4 <netrm:BufferRemaining
b5 xmlns:netrm="http://schemas.microsoft.com/ws/2006/05/rm">
b6 </netrm:BufferRemaining>
b7 </r:SequenceAcknowledgement>
Request phase defines a sequence and sends the first message (a3). In response, there is the appropriate acknowledgement present, which acks the first message (b3) with Lower and Upper attributes. Lines b4-b6 define a benign and super useful WCF implementation of flow control, which allows the sender to limit the rate of sent messages if service side becomes congested.
When the session is setup, WCF will have a really small time waiting window for acks. Therefore, if ack is not received during this period, the infrastructure will retry the message.
Duplex contracts work slightly differently. There, the acknowledgement interval can be set. This configuration option (config attribute is called acknowledgementInterval) is named inappropriately, since it controls the service and not the client side.
It does not define the time limit on received acknowledgements, but the necessary time to send the acknowledgments back. It allows grouping of sent acks, so that multiple incoming messages can be acked together. Also, the infrastructure will not necessarily honor the specified value.
Now consider the following scenario:
- The client is on a reliable network
- Network bandwidth is so thin that the sending message takes 20s to come through [1]
- Service instancing is set to Multiple
- The solution uses a request-reply semantics
[1] It does not matter whether the initiator is on a dial up, or the message is huge.
What happens?
Service initiator sets up a reliable session, then:
- First message is being sent
- Since the retry interval is really small [2], the message will not get to the other end and the acknowledgement will not bounce back in time
- First message is retried, now two messages are being transported
- No acks received yet
- First message is retried again
- Network bandwidth is even thinner
- First message is acknowledged
- First message retry is discarded on the service side
- Second message retry is discarded on the service side
[2] Under 3s.
The number of retry messages depends on the bandwidth and message size. It can happen that tens of messages will be sent before first acknowledgement will be received.
Adaptability algorithms
A good thing is that there are undocumented algorithms implemented for retry timeout. The implementation increases the reply timeout exponentially when the infrastructure detects that the network conditions demand more time (slow throughput) and allows reliable delivery (no losses). If loses are present the reply timeout decreases.
Retry timeout is actually calculated when establishing an RM session. It is based on the roundtrip time and is bigger if the roundtrip time is long.
So, when first messages in a session are exchanged, don't be too surprised to see a couple of message retries.